In the early stages of programmable technology development, there were two extremes of programmability. An extreme representation is the single-core CPU and DSP unit. These devices are programmed using software that contains a set of executable instructions. For programmers, these instructions are conceptually developed in a continuous manner, while advanced processors can reorder the instructions and extract instruction-level parallel processing operations from these sequential programs at runtime. In contrast, the other extreme of programmable technology is the FPGA. These devices are programmed by developing configurable hardware circuitry and executed in parallel. Designers using FPGAs are actually large-scale development of parallel applications with very granular granularity. Over the years, these two extremes have existed at the same time, and each type of programmable function is suitable for different application areas. However, recent technological trends indicate that there are better technologies that enable both programmable and parallel processing operations.
The second trend in software programmable devices is the emergence of complex hardware that extracts instruction-level parallel processing operations from sequential programs. The single core architecture inputs the instruction streams and executes them in the device. These devices have many parallel functional units. A large portion of the processor hardware must be dedicated to dynamically extracting parallel processing operations from sequential code. In addition, the hardware will try to compensate for memory delays. In general, programmers develop programs without considering the underlying memory structure of the processor, as if there were only large-scale unified fast memory. In comparison, the processor must handle the actual latency and link to the limited bandwidth of the external memory. In order to keep the functional unit capable of transmitting data, the processor must prefetch the data from the external memory and place it in the on-chip cache so that the data is closer to where it is to be calculated. With these technologies, after years of improvement in performance, this type of architecture has changed little.
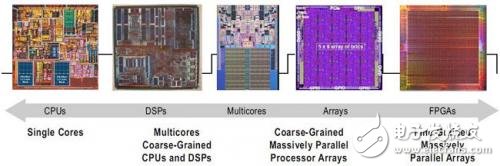
Figure 1. Recent trends in programmable and parallel technologies
In the traditional processor architecture, the advantages of these two trends are diminishing, we began to look for a variety of software programmable devices, these devices are developing very fast, as shown in Figure 1. The focus is on automatically extracting instruction-level parallel processing operations from runtime, and developing to explicitly find thread-level parallel processing operations during encoding. The emergence of highly parallel multicore devices, the general trend is to have multiple simple processors, many transistors are dedicated to calculations, rather than using a cache to extract parallel processing operations. These devices typically include multicore CPUs with 2, 4, or 8 cores, as well as GPUs with hundreds of simple cores for data parallel computing. To be able to achieve high performance on these multicore devices, programmers must clearly program the actual application in parallel. Each kernel must be assigned a certain amount of work so that all cores can work together to perform a certain calculation. This is what FPGA designers do when developing their advanced system architecture.
Considering the need to develop parallel programs in the new era of multi-core, OpenCL (Open Computing Language) was developed to develop cross-platform parallel programming standards. The OpenCL standard also naturally describes parallel algorithms implemented in FPGAs with abstract levels much higher than hardware description languages ​​(HDL) such as VHDL or Verilog. While there are many advanced synthesis tools that enable high-level abstraction, they all have the same basic problems. These tools use a continuous C program to produce a parallel HDL implementation. The difficulty is not obvious when developing HDL, but the difficulty in extracting thread-level parallel processing operations in FPGAs to improve performance is very large. The parallelism of FPGAs is very powerful, and the consequences of any failure when extracting parallelism as much as possible are very serious compared to other devices. The OpenCL standard addresses many of these issues and allows programmers to explicitly set and control parallel processing operations. The OpenCL standard can more naturally match the highly parallel nature of FPGAs than continuous programs described in pure C language.
The OpenCL application has two parts. The OpenCL main program is a pure software routine written in standard C/C++ that runs on any type of microprocessor. For example, such a processor can be an embedded soft core processor, a hard core ARM processor, or an external x86 processor in an FPGA.
At some point during the execution of this main software routine, a function may require a large amount of computation, which can benefit from the highly parallel acceleration of parallel devices such as CPU, GPU, FPGA and other devices. The feature to be accelerated is called the OpenCL kernel. These cores are written in standard C; however, structures are annotated to set parallel processing operations and memory levels. The example in Figure 2 performs vector addition on two arrays a and b, and writes the result back into the output array response. Each element of the vector uses parallel threads, and when accelerated with devices such as FPGAs with a large number of fine-grained parallel cells, the results can be quickly calculated. The main program uses the standard OpenCL API to support the transfer of data to the FPGA, call the FPGA core, and pass back the resulting data.
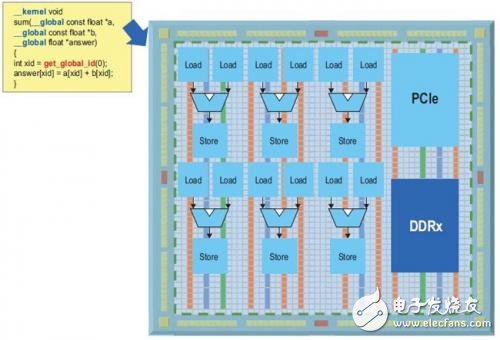
Figure 2. OpenCL example implemented on an FPGA
In FPGAs, kernel functions can be transferred to dedicated deep pipeline hardware circuits, which use the pipeline parallel processing concept, which is essentially multithreaded. Each of these pipelines can be replicated multiple times, providing more parallel processing than a pipeline.
The advantages of implementing the OpenCL standard on an FPGA
Using the OpenCL description to develop an FPGA design has many advantages over traditional methods based on HDL design. The process of developing a software programmable device typically involves conceiving, programming the algorithm in a high-level language such as C, and then using an automated compiler to build the instruction stream. The Altera SDK for OpenCL provides a design environment that makes it easy to implement OpenCL applications on an FPGA. As shown in Figure 3.
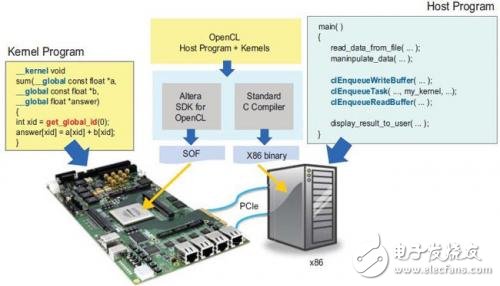
Figure 3. Introduction to the Altera SDK for OpenCL
This method can be compared with traditional FPGA design methods. In the traditional method, the designer's main job is to describe the hardware according to each cycle to implement its algorithm. Traditional processes involve establishing data paths, controlling these data paths through state machines, and using system-level tools to connect to the underlying IP core. Because of the constraints imposed by external interfaces, timing closure issues need to be addressed. The Altera SDK for OpenCL helps designers automate all of these steps, allowing them to focus on defining algorithms rather than focusing on tedious hardware design. Designed in this way, designers can easily migrate to new FPGAs with better performance and more power, because the OpenCL compiler turns the same high-level description into a pipeline, taking advantage of the new FPGA devices.
Using the OpenCL standard on an FPGA can significantly improve performance while reducing power consumption compared to current hardware architectures (CPU, GPU, etc.). In addition, the OpenCL standard, FPGA-based hybrid system (CPU + FPGA) has significant product and time-to-market advantages compared to traditional FPGA development methods using the underlying hardware description language (HDL) such as Verilog or VHDL.
We are offering Solar Led Street Light designed with precision to ensure optimum performance. Our offered light is manufactured with best quality components using latest techniques. Our offered light is rigorously checked at various quality parameters to ensure its flawlessness. Provided light is used to light the streets and is available in various specifications as per client`s requirement. We provide our light at an economical market rate.
50W Integrated Solar Street Lights
50W Integrated Solar Street Lights,Smart Solar Street Light,50W Solar Street Lights,50W Integrated Solar Street Lamp
Yangzhou Bright Solar Solutions Co., Ltd. , https://www.solarlights.pl