Speaker recognition, also known as speaker recognition, refers to automatically confirming whether a speaker is in the recorded set of speakers and further confirming the identity of the speaker by analyzing and processing the speaker's voice signal. The basic principle of speaker recognition is shown in Figure 1.
This article refers to the address: http://

According to the content of the speech, the speaker recognition can be divided into two types: text-independent and text-dependent. The text-independent recognition system does not stipulate the speaker's pronunciation content, and the model establishment is relatively difficult, but the user is convenient to use. The speaker recognition system related to the text requires the user to pronounce according to the specified content, and the recognition must also be pronounced according to the specified content, so that a better recognition effect can be achieved.
With the development of network technology, VoIP (Voice over IP) technology for transmitting voice over the Internet has developed rapidly and has become an important means of daily communication. More and more users abandon traditional communication methods through computer networks. The medium communicates with the voice. Due to the characteristics of VoIP working mode, voice is processed by voice coding and decoding in the transmission, and the VoIP device port also needs to process multiple channels and massive compressed voice data. Therefore, the VoIP speaker recognition technology mainly studies how to perform speaker recognition for decoding parameters and compressed code streams at high speed and low complexity.
The existing research on the recognition method of the code domain speaker mainly focuses on the extraction of the speech feature parameters in the coding domain. The Hong Kong Polytechnic University studies the information from the G.729 and G.723 encoded bitstreams and residuals, and uses the scores. The method of compensation. The University of Science and Technology of China mainly studies speaker recognition for AMR speech coding. Northwestern Polytechnical University studied the compensation algorithm for different speech coding differences in speaker confirmation, and studied the method of extracting parameters directly in the G.729 encoded bit stream. The speaker model mainly uses the GMM-UBM (Gaussian Mixture Model-Universal Background Model) which is the most widely used in traditional speaker recognition. The application effect of GMM-UBM is closely related to the number of mixed elements. On the basis of ensuring the recognition rate, the processing speed cannot meet the needs of high-speed speaker recognition in VoIP environment.
This paper studies the real-time recognition of speakers in the G.729 coding domain in VoIP voice stream, and successfully applies the DTW recognition algorithm to the text-related speaker real-time recognition in the G.729 coding domain.
Feature extraction in 1 G.729 encoded bitstream
1.1 G.729 coding principle ITU-T announced the G.729 code in March 1996, its coding rate is 8 kb / s, using the structure of the digital excitation linear prediction technology (CS-ACELP), the coding results can be 8 The synthesized sound quality at a bit rate of kb/s is not lower than the level of 32 kb/s ADPCM. The algorithm latency of G.729 is 15 ms. Because of its high voice quality and low latency, the G.729 codec is widely used in various fields of data communication, such as VoIP and H.323 online multimedia communication systems.
The encoding process of G.729 is as follows: the digital speech signal input with 8 kHz samples is preprocessed by high-pass filtering, linear prediction analysis is performed every 10 ms frame, the 10th-order linear prediction filter coefficients are calculated, and then these coefficients are converted into line spectra. The (LSP) parameters are quantized using a two-stage vector quantization technique. In the adaptive codebook search, the error is detected by the error perceptual weighting of the original speech and the synthesized speech. The fixed codebook is based on the digital agency. The excitation parameters (adaptive codebook and fixed codebook parameters) are determined once per subframe (5 ms, 40 samples).
1.2 Feature parameter extraction The LSP parameters can be obtained by dequantizing directly from the G.729 coded stream according to the quantization algorithm. Since the speaker recognition system in the latter stage also needs the excitation parameters, and the interpolation of the LSP is smoothed in the calculation process of the excitation parameters, in order to accurately match the channel and the excitation parameters in the feature vector, the dequantization is required. The LSP parameters are interpolated and smoothed. 

In this paper, the inverse cosine LSF of the LSP(1) parameter of the first subframe in the G.729 coded frame and the LPC and LPCC parameters converted by it are selected as the channel feature parameters.
Reference [1] found that the recognition feature was added to the speech gain parameter in the G.729 compressed frame, and the speaker recognition performance decreased. The gain parameters GA1, GB1, GA2, and GB2 in the G.729 compressed code stream feature are removed. It is found that the feature vector scheme X=(L0, L1, L2, L3, P1, P0, P2) is used when the gain parameter is removed. The recognition performance has been improved, so the G.729 compressed code stream feature finally adopted in this paper is X=(L0, L1, L2, L3, P1, P0, P2), which is 7-dimensional.
2 Dynamic Time Warping (DTW) Recognition Algorithm <br> Dynamic Time Warping (DTW) is a nonlinear regularization technique that combines time warping and distance measurement calculation. The algorithm is based on the dynamic programming idea and solves the problem of template matching with different pronunciation lengths.
Algorithm principle: It is assumed that the test speech and the reference speech are represented by R and T respectively. In order to compare the similarities between them, the distance D[T, R] between them can be calculated, and the smaller the distance, the higher the similarity. In the specific implementation, the voice is pre-processed, and then R and T are divided into frame series at the same time interval: 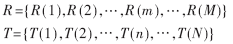
Then use dynamic programming for identification. as shown in picture 2.
The frame numbers n=1,...,N of the test template are marked on the horizontal axis of a two-dimensional Cartesian coordinate system, and the frame numbers m=1,...,M of the reference template are marked on the vertical axis, These horizontal and vertical lines, which represent the integer coordinates of the frame number, form a grid. Each intersection (n, m) in the grid represents the intersection of a frame in the test template with a frame in the training template. . The dynamic programming algorithm can be summarized as finding a path through several grid points in the grid. The grid point through which the path passes is the frame number of the distance calculation in the test and reference templates. 
The whole algorithm mainly comes down to calculating the similarity between the test frame and the reference frame and the vector distance accumulation of the selected path.
The identification process is shown in Figure 3.
3 Experimental results and performance analysis and conclusions <br> In order to test the above recognition performance, a fixed-text speaker recognition test was carried out. In the experiment, a total of 300 recording files were used by 30 speakers in the telephone channel 863 corpus, and the file format was 16 bit linear PCM. To simulate a voice compressed frame in VoIP, the original voice file is compressed using a G.729 vocoder. Use one file per speaker to train as a template. The test voice length is 10 s to 60 s with a total of 11 test time standards at intervals of 5 s. Thus, there are 30 templates in the template library, and there are 270 test voices. The configuration of the microcomputer is: CPU Pentium 2.0 GHz, memory 512 MB.
In the experiment, M and N take 64. Through the matching between the templates, it is determined that the decision threshold is 0.3, and the recognition effect is the best.
In order to compare the recognition performance of the DTW algorithm, a GMM model widely used in traditional speaker recognition is used as a comparative experiment, wherein the GMM model uses the same coded stream feature as the DTW algorithm.
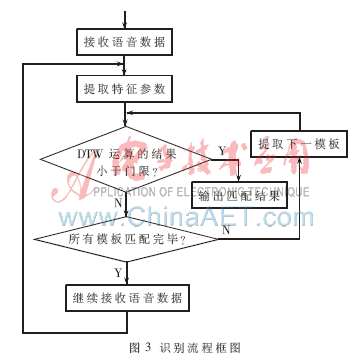
Figure 4 shows a comparison of the misrecognition rates of text-related speakers based on the DTW recognition method and the GMM model (mixed number 64) to identify the G.729 coding scheme 863 corpus. The abscissa represents the duration of the test speech, and the ordinate represents the recognition misrecognition rate. The experimental results show that in the text-related speaker recognition, the recognition rate based on DTW algorithm is higher than the GMM model in most cases, and the advantage is more obvious with the increase of test speech.
To compare the time performance and total time performance of feature extraction, the experimental conditions are as follows:
(1) The voices of the selected 50 speakers are only extracted, and the total length of the test speech is about 25 minutes;
(2) Decoding and identification of the test speech and identification of the encoded stream, the number of templates is 10;
(3) The microcomputer is configured as: CPU Pentium 2.0 GHz, memory 512 MB.
Table 1 shows the comparison results of feature extraction time, and Table 2 shows the comparison results of speaker recognition time.
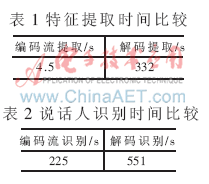
It can be seen from the experimental results that the feature extraction time and recognition (upper page 121) in the encoded bit stream are much smaller than the decoded speech feature extraction time and recognition time, which satisfies the needs of real-time speaker recognition.
In the text-related speaker recognition, compared with the GMM model using the same G.729 compressed code stream feature, the recognition rate and processing efficiency of the DTW method are higher than the GMM model, and can be applied to the VoIP network supervision in real time.
references
[1] Shi Ruliang. Research on speaker recognition technology in coding domain [D]. Zhengzhou: PLA Information Engineering University, 2007.
[2] PETRACCA M, SERVETTI A, DEMARTIN J C. Performance analysis of compressed-domain automatic speaker recognition as a function of speech coding technique and bit rate [A]. In: International Conference on Multimedia and Expo (ICME) [C] Toronto, Canada, 2006: 1393-1396.
[3] Shi Ruliang, Li Yicheng, Zhang Lianhai, et al. Speaker recognition based on coded bit stream[J]. Journal of Information Engineering University, 2007, 8(3): 323-326.
[4] Wang Bingxi, Qu Dan, Peng Yu. The basis of practical speech recognition [M]. Beijing: National Defence Industry Press, 2004: 264-286.
[5] Li Shaomei, Liu Lixiong, Chen Hongbiao. Improved DTW Algorithm in Real-Time Speaker Discrimination System[J]. Computer Engineering, 2008, 34(4): 218-219.
[6] DUNN RB, QUATIERI TF, REYNOLDS D A. et al. Speaker recognition from coded speech in matched and mismatched conditions [A]. In: Proc. Speaker Recognition Workshop'01 [C]. Grete, Greece, 2001:115 -120.
[7] AGGARWAL CC, OLSHEFSKI D, SAHA D et al. CSR: Speaker recognition from compressed VoIP packet stream [A]. In: International Conference on Multimedia and Expo (ICME) [C]. Amsterdam, Holand, 2005: 970- 973.
In addition to Instax Camera Accessories, we also sell Other Accessories: Fijifilm wireless printer crystal case and PU protective case, Instax camera CR2 battery kit (for Instax Mini 25 / Instax 50 / Instax Mini 70 / SP-1, including charger and battery) , IQOS electronic cigarette protection leather case(Long Wallet and Hanging Waist Case).
Other Accessories
Action Camera Waterproof Shell Case,Camera Wrist Hand Band Mount Strap,Camera Support Accessories,Camera Gopros Accessories
GuangZhou CAIUL Digital Products CO,.LTD. , http://www.caiul-instax.com